
The release of GPT-4 brings remarkable advancements in language model capabilities. However, it is essential to recognize that the model still has limitations similar to its predecessors. Despite significant improvements in factuality, OpenAI highlights that users must exercise caution, particularly in high-stakes contexts.
OpenAI’s internal factual assessment across nine categories reveals GPT-4 outperforms the latest GPT-3.5 by 19 percentage points (a 40% improvement). A 100% accuracy in the evaluation indicates the model’s answers align with ideal human responses in each category.
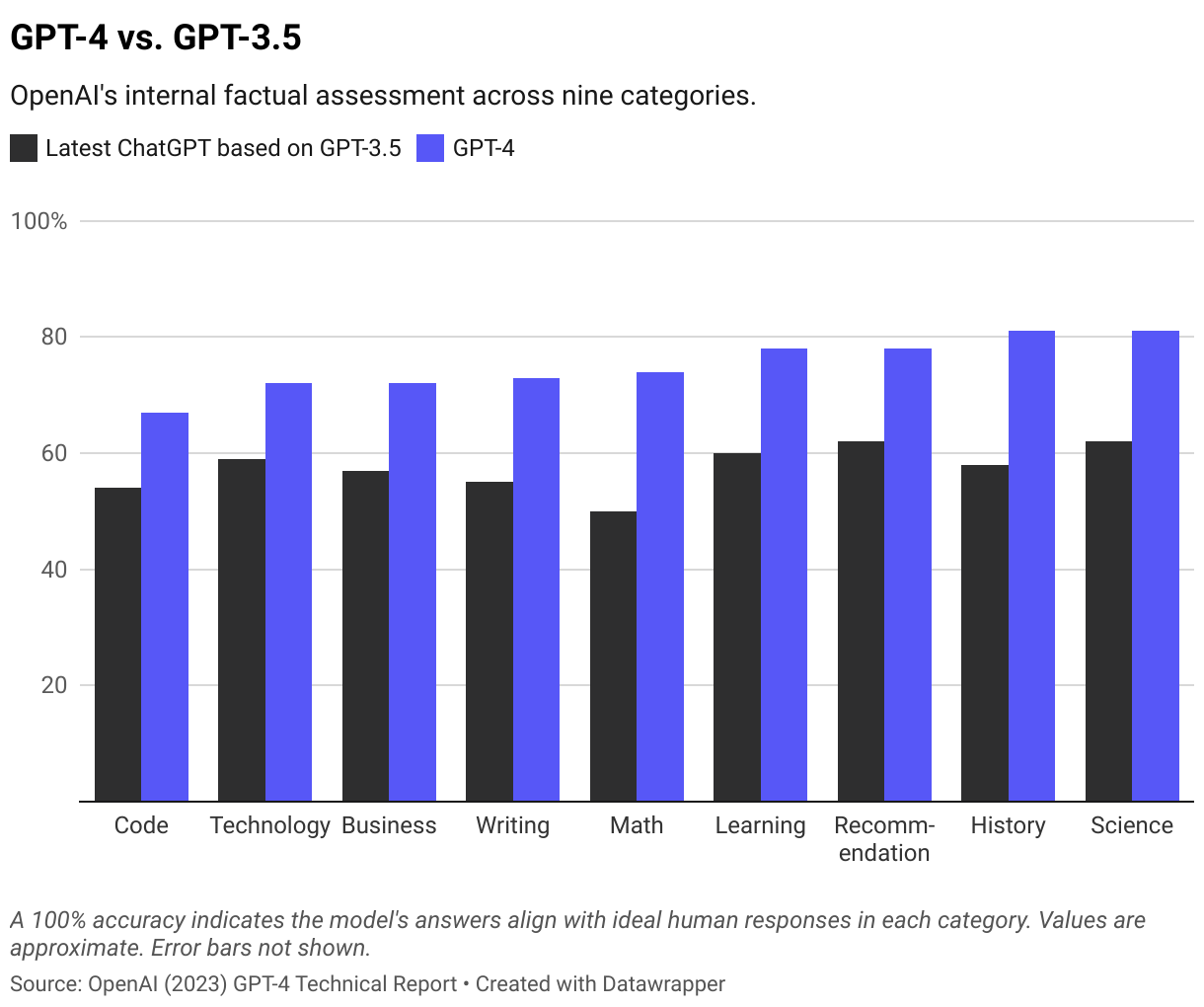
Yet despite these advancements OpenAI said in the release that:
“it is not fully reliable (it “hallucinates” facts and makes reasoning errors). Great care should be taken when using language model outputs, particularly in high-stakes contexts, with the exact protocol (such as human review, grounding with additional context, or avoiding high-stakes uses altogether) matching the needs of specific applications.”